

{Dies ist der 10. Teil einer Miniserie. Ich empfehle am Anfang zu beginnen und sich dann Post für Post nach vorne zu hangeln. Hier geht´s zum Nr. (1)- Post }
Wir wollen einen Nutzomaten nicht nur Modellieren, sondern in der Hand halten und anwenden. Möglichst schnell. Je enger der Anwendungsfall, desto besser kann man das Nutzomat-Kalkül brauchbar abbilden. Der sinnvollste erste Deliverable wäre:
Ein Entscheidungsprototyp, der 2–4 Alternativen anhand der vier Nutzenarten plus Kosten individuell vergleicht und die Entscheidung erklärt. Das ist klein genug, um baubar zu sein, und groß genug, um echten Wert zu stiften.
Das findet auch die KI und schlägt mir vor: „Ich kann dir als nächsten Schritt ein konkretes App-Konzept mit Datenmodell, Screens, Fragenkatalog und Rechenlogik als MVP-Blueprint ausarbeiten.“
Und ich sach, naiv wie ich bin: Go!
***************************************
Ab hier: fast kompletto KI.
Nur an einigen Stellen habe ich unbedingt zu ergänzendes rot eingefügt!
Und formatiert habe ich auch etwas.
***************************************
1. Produktdefinition
Arbeitsname:
Nutzomat Decision Engine
MVP-Anwendungsfall
Am besten zuerst eine enge Entscheidungsklasse.
Für den MVP würde ich eine einzige Entscheidungsklasse wählen, z. B. „Vergleich von 2 bis 4 Alternativen bei wichtigen privaten oder beruflichen Entscheidungen“ Das ist breit genug für Nutzenkalküle, aber eng genug, um nicht sofort im Theorie-Sumpf zu versinken.
2. Kernmodell der App
Berechnungslogik für jede Alternative A:
Transaktionswert(A) = Gesamtnutzen(A) – Gesamtkosten(A)
mit:
Gesamtnutzen(A) = Ergebnisnutzen + Prozessnutzen + Persönlichkeitsnutzen + Prosumtionsnutzen und Gesamtkosten(A) = Inputkosten + Transaktionskosten + Persönlichkeitsnutzen + Prosumtionsnutzen
Dabei: TV(User, Situation, Alternative)
Also:
- userabhängig
- situationsabhängig
- alternativabhängig
Das ist die eigentliche Architekturidee.
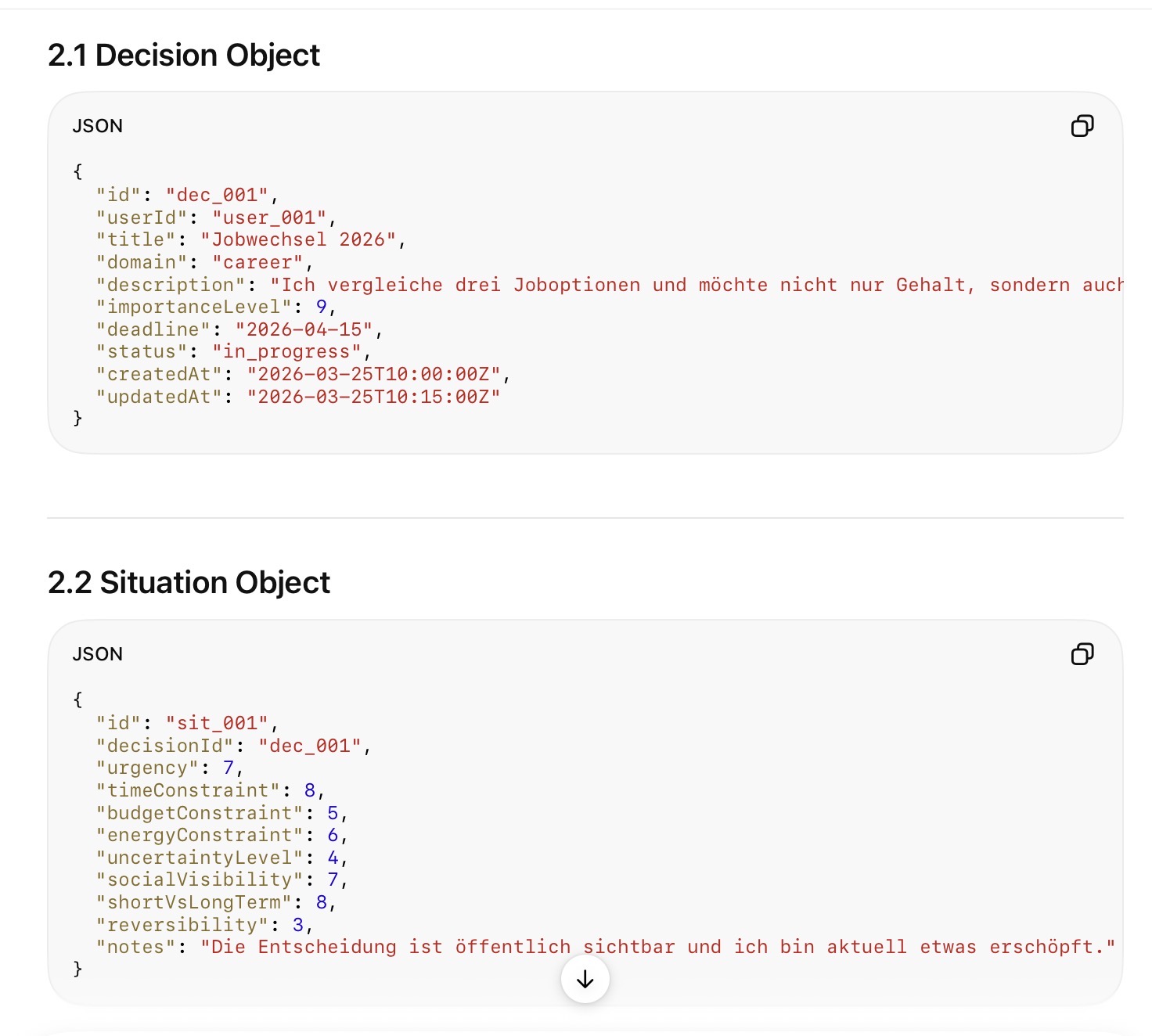
3. Das Datenmodell
A. User
Beschreibt stabile oder halb-stabile Präferenzmuster.
Felder:
- user_id
- name / alias
- decision_profile_version
- time_horizon_preference
- risk_tolerance
- identity_sensitivity
- process_orientation
- future_orientation
- resource_sensitivity
- social_validation_relevance
- learning_orientation
- weight_result
- weight_process
- weight_personality
- weight_prosumption
- weight_input_cost
- weight_transaction_cost
Diese Gewichte sind zu Beginn Startwerte, später lernbar.
B. Situation
Beschreibt den konkreten Entscheidungskontext.
Felder:
- situation_id
- user_id
- title
- domain
- urgency
- emotional_state
- social_visibility
- uncertainty_level
- budget_constraint
- time_constraint
- energy_constraint
- reversibility
- importance_level
- decision_deadline
- notes
Die Situation moduliert die Gewichte.
Beispiel:
- hoher Zeitdruck → Prozess-/Transaktionskosten relevanter
- hohe soziale Sichtbarkeit → Persönlichkeitsnutzen relevanter
- langfristige Entscheidung → Prosumtionsnutzen relevanter
C. Alternative
Die tatsächlich vergleichbare Option.
Felder:
- alternative_id
- situation_id
- label
- category
- description
- price_estimate
- time_required
- effort_required
- uncertainty_estimate
- expected_outcome_summary
- process_summary
- identity_summary
- future_value_summary
D. Ratings
Hier liegen die Antworten des Nutzers auf die Bewertungsfragen.
Felder:
- rating_id
- user_id
- situation_id
- alternative_id
- dimension_type
- item_key
- intensity_score
- certainty_score
- relevance_score
- timestamp
E. Computed Scores
Von der Engine berechnete Werte.
Felder:
- score_id
- alternative_id
- result_benefit_score
- process_benefit_score
- personality_benefit_score
- prosumption_benefit_score
- input_cost_score
- transaction_cost_score
- personality_cost_score
- prosumption_cost_score
- total_benefit_score
- total_cost_score
- transaction_value_score
- confidence_score
- recommendation_rank
F. Outcome / Learning
Um das Modell später zu kalibrieren.
Felder:
- outcome_id
- situation_id
- chosen_alternative_id
- actual_decision
- post_decision_satisfaction
- regret_level
- actual_outcome_quality
- process_experience
- identity_fit_afterwards
- future_value_realized
- reflection_notes
Das ist Gold wert. Sonst bleibt die App nur ein hübscher Theoriegenerator.
4. Operationalisierung der Nutzenarten
Jetzt das Herzstück: Welche Fragen muss die App stellen?
Wichtig: Der Nutzer sollte nicht abstrakte Fachbegriffe sehen wie „Prosumtionsnutzen“.
Die App muss intern sauber sein, aber außen alltagstauglich.
Skala
Für den MVP überall:
- 0 bis 10 für Intensität
- 0 bis 10 für Sicherheit
- 0 bis 10 für aktuelle Wichtigkeit
So bekommst du je Item drei Werte:
- Wie stark?
- Wie wahrscheinlich/sicher?
- Wie wichtig gerade?
A. Ergebnisnutzen
Frageebene: Was kommt dabei für mich konkret heraus?
Beispielfragen:
- Wie stark hilft dir diese Option, dein Ziel zu erreichen?
- Wie nützlich ist das erwartete Ergebnis für dich?
- Wie groß ist der direkte Gewinn, wenn diese Option gelingt?
- Wie wahrscheinlich ist es, dass dieses Ergebnis wirklich eintritt?
- Wie wichtig ist dir dieses Ergebnis gerade jetzt?
Optionale Unterdimensionen:
- Problemlösung
- Zielerreichung
- Komfortgewinn
- materielle Verbesserung
- direkte Bedürfnisbefriedigung
B. Prozessnutzen
Frageebene: Wie ist der Weg dorthin für mich?
Beispielfragen:
- Wie angenehm wäre der Weg zu diesem Ergebnis?
- Wie sehr würdest du die Durchführung genießen?
- Wie gut passt der Ablauf zu deiner Art?
- Wie leicht oder reibungslos fühlt sich diese Option an?
- Wie stark würdest du dich währenddessen unter Druck oder Friktion fühlen?
Optionale Unterdimensionen:
- Spaß
- Einfachheit
- Fairness
- Kontrolle
- Ästhetik
- Erlebnisqualität
C. Persönlichkeitsnutzen
Frageebene: Was macht diese Option mit meinem Selbstbild?
Beispielfragen:
- Wie gut passt diese Option zu dem Menschen, der du sein willst?
- Wie sehr würdest du dich mit dieser Entscheidung „richtig“ fühlen?
- Wie stark stärkt diese Option dein Selbstvertrauen?
- Wie sehr unterstützt diese Option dein Selbstbild oder deine Identität?
- Wie positiv würdest du durch diese Entscheidung auf dich selbst blicken?
Optionale Unterdimensionen:
- Identitätsfit
- Autonomie
- Kompetenzgefühl
- soziale Anerkennung
- moralische Stimmigkeit
- Stolz
D. Prosumtionsnutzen
Frageebene: Was baue ich dadurch auf, das mir später hilft?
Beispielfragen:
- Wie sehr hilft dir diese Option, Fähigkeiten oder Erfahrung aufzubauen?
- Wie stark verbessert sie deine zukünftigen Chancen?
- Wie sehr spart dir diese Option später Aufwand oder Kosten?
- Wie stark erzeugt sie später nutzbare Kontakte, Reputation oder Wissen?
- Wie wahrscheinlich ist es, dass dir der heutige Aufwand künftig mehrfach nützt?
Optionale Unterdimensionen:
- Lerngewinn
- Reputationsgewinn
- Netzwerkeffekt
- Wiederverwendbarkeit
- Zugang zu Chancen
- künftige Kostensenkung
E. Inputkosten
Frageebene: Was muss ich direkt investieren?
Beispielfragen:
- Wie hoch sind die direkten finanziellen Kosten?
- Wie viel Zeit musst du investieren?
- Wie viel Energie kostet dich diese Option?
- Wie stark belastet sie deine Aufmerksamkeit?
- Wie stark musst du auf andere Dinge verzichten?
F. Transaktionskosten
Frageebene: Wie viel Reibung, Unsicherheit und Komplexität entsteht?
Beispielfragen:
- Wie groß ist der Aufwand, um diese Option überhaupt umzusetzen?
- Wie unsicher fühlt sich diese Option an?
- Wie kompliziert ist die Entscheidung oder Durchführung?
- Wie hoch ist das Risiko unerwünschter Folgen?
- Wie viel mentale Belastung erzeugt diese Option?
- Wie viel Such-, Abstimmungs- oder Rechtfertigungsaufwand steckt darin?
G. Prosumtionskosten
tbd.
F.Persönlichkeitskosten
tbd.
5. Das Scoring-Modell
Für den MVP sollte die Berechnung stark genug, aber noch erklärbar sein.
Pro Item
Jedes Item hat:
- Intensität I
- Sicherheit S
- Relevanz R
Dann:
Item-Beitrag = I × S × R
Für bessere Skalierung alles vorher auf 0–1 normieren.
Also praktisch:
Item-Beitrag = (I/10) × (S/10) × (R/10)
Pro Dimension
Dann pro Nutzen- oder Kostenart:
Dimensionscore = Durchschnitt oder gewichtete Summe aller Item-Beiträge
Personengewichtung
Jede Dimension bekommt ein user-spezifisches Gewicht.
Beispiel:
- Ergebnisnutzen: 1.1
- Prozessnutzen: 0.8
- Persönlichkeitsnutzen: 1.3
- Prosumtionsnutzen: 1.4
- Inputkosten: 1.0
- Transaktionskosten: 1.2
- Persönlichkeitskosten 1.3
- Prosumtionskosten1.4
Situationsmodulation
Dann moduliert die Situation zusätzlich.
Beispiel:
- hoher Zeitdruck → Prozesskostenfaktor +0.3
- hohe Unsicherheit → Transaktionskostenfaktor +0.4
- langfristige Weichenstellung → Prosumtionsfaktor +0.5
- öffentlich sichtbare Entscheidung → Persönlichkeitsfaktor +0.4
Endberechnung
Dann:
Gesamtnutzen =
- Ergebnisnutzen × user_weight × situation_factor
- plus Prozessnutzen × user_weight × situation_factor
- plus Persönlichkeitsnutzen × user_weight × situation_factor
- plus Prosumtionsnutzen × user_weight × situation_factor
Gesamtkosten =
- Inputkosten × user_weight × situation_factor
- plus Transaktionskosten × user_weight × situation_factor
- plus Persönlichkeitskosten x use_weight x situation_factor
- plus Prosumtionsnutzen x use_weight x situation_factor
Dann:
Transaktionswert = Gesamtnutzen – Gesamtkosten
Confidence Score
Zusätzlich:
Confidence Score = Durchschnitt aller certainty-Werte
Das ist wichtig, weil eine Empfehlung mit hoher Punktzahl, aber schwacher Sicherheit anders zu behandeln ist als eine stabile Empfehlung.
6. Die Ausgabe-Logik
Die App darf nicht nur Zahlenspuckmaschine sein.
Sie muss drei Dinge liefern:
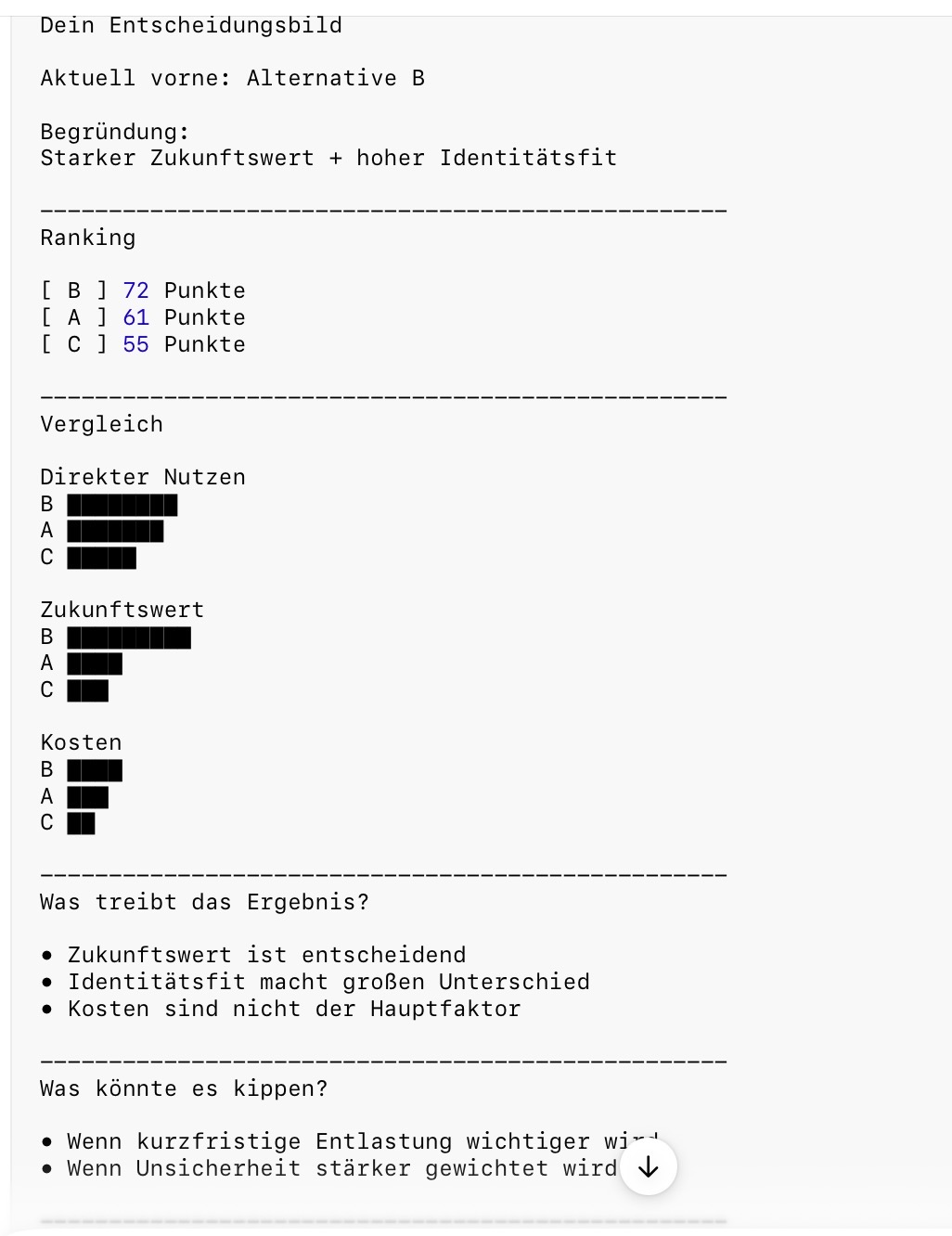
A. Ranking
- Alternative 1
- Alternative 2
- Alternative 3
B. Treiberanalyse
Warum ist A vorne?
Beispiel:
- starke Zukunftsvorteile
- hoher Identitätsfit
- moderate direkte Kosten
- aber erhöhte Unsicherheit
C. Sensitivität
Was würde das Ergebnis kippen?
Beispiel:
- Wenn Zeitaufwand doch höher ist, fällt A hinter B
- Wenn Zukunftschancen wichtiger werden, gewinnt A deutlicher
- Wenn kurzfristige Entlastung Priorität hat, gewinnt C
Das ist extrem wertvoll, weil es das implizite Kalkül explizit macht.
7. UX-Blueprint
Screen 1: Entscheidung anlegen
Fragen:
- Worum geht es?
- Welche Entscheidung willst du treffen?
- Wie wichtig ist sie?
- Bis wann musst du entscheiden?
Screen 2: Alternativen eingeben
- Alternative A
- Alternative B
- Alternative C
- optional D
Je Alternative:
- Name
- Kurzbeschreibung
- grobe Kosten
- erwartetes Hauptergebnis
Screen 3: Situation erfassen
Fragen:
- Wie dringend ist die Entscheidung?
- Wie groß ist dein Zeitdruck?
- Wie stark bist du emotional involviert?
- Wie sichtbar ist die Entscheidung für andere?
- Ist dir gerade eher kurzfristige Entlastung oder langfristiger Aufbau wichtig?
- Wie knapp sind Geld, Zeit, Energie aktuell?
Screen 4: Persönliche Prioritäten
Fragen:
- Was ist dir bei solchen Entscheidungen generell besonders wichtig?
- Wie stark zählt für dich, dass etwas zu deinem Selbstbild passt?
- Wie stark zählt für dich, dass sich der Weg gut anfühlt?
- Wie stark zählst du langfristige Folgeeffekte mit?
- Wie stark belastet dich Unsicherheit normalerweise?
Damit erzeugst du die Startgewichte.
Screen 5: Alternative bewerten
Für jede Alternative ein kompakter Flow:
Bereich 1:
- Was bringt es dir direkt?
Bereich 2:
- Wie ist der Weg dorthin?
Bereich 3:
- Was macht es mit dir?
Bereich 4:
- Was baut es für später auf?
Bereich 5:
- Was kostet es dich direkt?
Bereich 6:
- Welche Reibung, Unsicherheit und Komplexität hat es?
Bereich 7 + 8
tbd.
Screen 6: Ergebnis
Visualisierung:
- Transaktionswert je Alternative
- 4 Nutzenarten + 2 Kostenarten als Balken
- dominante Entscheidungstreiber
- Warnhinweise bei Unsicherheit
- Textzusammenfassung
Beispieltext:
„Alternative B liegt vorn, weil sie für dich aktuell den höchsten Persönlichkeits- und Prosumtionsnutzen bei tragbaren Transaktionskosten bietet. Alternative A ist kurzfristig einfacher, verliert aber deutlich bei Zukunftswert.“
Screen 7: Nachverfolgung
Einige Tage oder Wochen später:
- Wofür hast du dich entschieden?
- Wie zufrieden bist du rückblickend?
- War das Ergebnis wie erwartet?
- War der Weg schlimmer oder besser als gedacht?
- Hat es dir später tatsächlich etwas gebracht?
Damit lernst du die Gewichte nach.
8. Lernlogik
Am Anfang ist das Modell halbmanuell.
Mit der Zeit wird es persönlicher.
Phase 1: Regelbasiert
- feste Fragen
- feste Startgewichte
- einfache Situationsmodifikatoren
Phase 2: Personalisierung
- Gewichte werden anhand vergangener Entscheidungen angepasst
- z. B. erkennt die App:
- Nutzer überschätzt regelmäßig Ergebnisnutzen
- Nutzer unterschätzt regelmäßig Transaktionskosten
- Nutzer ist zufriedener, wenn Persönlichkeitsnutzen hoch war
Phase 3: Vorhersageunterstützung
Später kann die App vor dem vollständigen Ausfüllen schon Hinweise geben:
- „Bei ähnlichen Entscheidungen war für dich Zukunftswert oft entscheidend.“
- „Du bereust Entscheidungen öfter, wenn du den Prozess unterschätzt.“
******************
Tja und dann hört das ganze gar nicht mehr auf: erst ein komplettes Product Requirement Document (PRD) für die Nutzomat Decision Engine (MVP) mit User Stories, Datenmodell, Formellogik, Screen-Flow und MVP-Scope in Team-tauglicher Form, dann ein konkretes Wireframe-Set für den MVP — mit Screens, UI-Struktur, Textbausteinen, Formularfeldern, Button-Labels und Ergebnislogik, dann ein konkretes App-Konzept mit Datenmodell, Screens, Fragenkatalog und Rechenlogik als MVP-Blueprint, dann ein Figma-Handoff-Format und ein echtes Delivery-Paket mit drei Artefakten auf einmal (1. User Stories + Acceptance Criteria, 2. JSON-Struktur für Frontend/Backend, 3. Seed-Daten für einen Demo-Case) und sogar einen konkreten 6-Wochen-Umsetzungsplan mit Sprints, Rollen, Deliverables und Done-Kriterien.



Und spätestens jetzt war klar: ich brauche Hilfe, wenn der Nutzomat Wirklichkeit werden soll. Und das soll er definitiv…